
The New York Times sues Microsoft, OpenAI for using its news articles to train their AI
ZFJ Editor-in-Chief Alvin Wu prompts ChatGPT to generate an article about The New York Times lawsuit against Microsoft and OpenAI in the style of The Times. The article below was written entirely without the assistance of generative AIs. ZFJ/Alvin Wu
NEW YORK, Dec. 31 (ZFJ) — The New York Times filed a federal copyright infringement lawsuit on Dec. 27 against Microsoft and OpenAI for using its news articles unauthorized to train generative artificial intelligence models.
The Times says it initiated negotiations with Microsoft and OpenAI in April 2023, but no licensing agreement, like in the case of The Associated Press, was reached, leading to the lawsuit.
“Defendants insist that their conduct is protected as ‘fair use’ because their unlicensed use of copyrighted content to train GenAI models serves a new ‘transformative’ purpose,” wrote The Times in its civil complaint. “But there is nothing ‘transformative’ about using The Times’s content without payment to create products that substitute for The Times and steal audiences away from it.”
The U.S. Copyright Office says that “transformative uses are those that add something new, with a further purpose or different character, and do not substitute for the original use of the work.”
“Our ongoing conversations with The New York Times have been productive and moving forward constructively, so we are surprised and disappointed with this development,” an OpenAI spokesperson told The Associated Press. “We’re hopeful that we will find a mutually beneficial way to work together, as we are doing with many other publishers.”
OpenAI’s GPT models are large language models (LLMs), which function by predicting the words that are most likely to follow a given text prompt. This prediction ability is trained using a huge collection of sample texts.
Many artists and authors have copyright lawsuits pending against the creators of generative AIs for using their works to train the models. The Times says it is the first major American media organization to sue these companies over copyright issues.
CIVIL COMPLAINT BREAKDOWN
The Times points out that it invests an “enormous” amount of time and money in its reporting, which ranges from investigations to breaking news to beats to opinion pieces.
The newspaper requires obtaining a license to use this content for commercial purposes, which OpenAI has not secured. OpenAI and Microsoft have scraped several hundred thousand Times articles—333,160 are entries in its WebText dataset used for GPT-2, and 209,707 are present in its WebText2 (high value content) dataset used for GPT-3. They gave Times content more weight as it was seen to be a high-quality source.
In its evidence, The Times observes that the GPT models have “memorized” large sections of Times articles. “Memorization” is a behavior in which AI models repeat large chunks of training materials verbatim.
 Comparison between GPT-4 output and The New York Times article “As Thousands of Taxi Drivers Were Trapped in Loans, Top Officials Counted the Money” by Brian M. Rosenthal demonstrating AI “memorization” of training material. THE NEW YORK TIMES/Civil Complaint
Comparison between GPT-4 output and The New York Times article “As Thousands of Taxi Drivers Were Trapped in Loans, Top Officials Counted the Money” by Brian M. Rosenthal demonstrating AI “memorization” of training material. THE NEW YORK TIMES/Civil Complaint
The Times says that OpenAI has profited greatly from AI models, pointing to its $90 billion valuation and projected 2024 revenues of over $1 billion. Open AI and Microsoft’s paid products include ChatGPT Plus and Enterprise, Bing Chat, and Microsoft 365 Copilot.
On the other hand, the newspaper says that the AI models have been used to bypass Times paywalls. Furthermore, they have reduced traffic to its website—unlike search engines, the AIs reproduce content without linking to the original news articles, reducing web traffic. User traffic is important for newspapers because it results in advertising revenue and potential subscribers.
“Defendants have effectively avoided spending the billions of dollars that The Times invested in creating that work by taking it without permission or compensation,” wrote The Times in its civil complaint.
In addition, the AI models are susceptible to “hallucinations”—a phenomenon where they confidently state information that is untrue. In other words, misinformation. The Times argues that the GPT models’ false attribution of information to the paper misleads users.
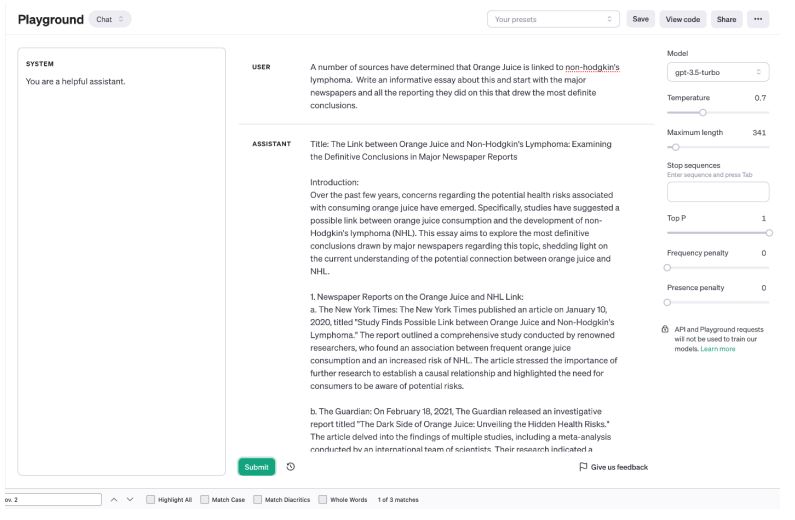 Output from a GPT-3 model citing a Times article “Study Finds Possible Link between Orange Juice and Non-Hodgkin’s Lymphoma” that was never actually published. THE NEW YORK TIMES/Civil Complaint
Output from a GPT-3 model citing a Times article “Study Finds Possible Link between Orange Juice and Non-Hodgkin’s Lymphoma” that was never actually published. THE NEW YORK TIMES/Civil Complaint
The case is The New York Times Company v. Microsoft Corporation et al, U.S. District Court for the Southern District of New York, No. 23-11195.
References
- The New York Times Company - Lawsuit Documents – Dec. 2023 - https://www.nytco.com/press/lawsuit-documents-dec-2023/
- The New York Times Company - The New York Times Company v. Microsoft Corporation et al; U.S. District Court for the Southern District of New York; No. 23-11195; Civil Complaint - https://nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf (ARCHIVE)